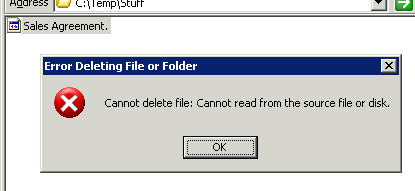
I’ve finally solved a problem that’s been bugging me for years. One of our file shares ended up with several undelete-able files. Attempting to delete them results in “Error Deleting File or Folder – Cannot delete file: Cannot read from the source file or disk“.
Note: Windows 7’s version of this message is something like:
Could not find this item: This is no longer located in C:Blah. Verify the item’s location and try again.
Even going to the file’s properties to check permissions presented a very blank properties dialog. And a CHKDSK didn’t sort thing out either.
It turns out the problem was: the filename ended with a dot, e.g. it was something like “C:TempStuffSales Agreement.“. As far as Windows is concerned this is an invalid file name: so although it gets reported in a directory listing, the standard Windows APIs for manipulating files subsequently deny its existence.
So how did this file get created in the first place? The answer: a Mac. The file was on a file share which had been accessed by a Mac user. Macs tend to write all sorts of metadata to extra “._DSStore” files and suchlike and had left this file behind.
So if Windows doesn’t appear to allow these file names, how did they get to be created? Well, it turns out that NTFS allows all sort of file name/path weirdness that Windows, or specifically the Win32 API, doesn’t allow. For example, NTFS actually allows file paths up to 32K but Windows restricts file paths to no more than 260 characters (MAX_PATH). I suppose this is all for DOS/Windows 9x backwards compatibility. As these files were being accessed over a file share I guess the usual Win32 checks are bypassed.
But thankfully you can get Win32 to ignore these checks by prefixing your file paths with \?, (ie. C:TempSomeFile.txt becomes \?C:TempSomeFile.txt) which I discovered after reading this blog post about long paths in .NET.
So at a command prompt (Start > All Programs > Accessories > Command Prompt) I was able to delete the file using:
del "\?C:TempStuffSales Agreement."
Note: On Windows 7 it seems you can just use wildcards without the \? trick to delete the offending files: e.g.
del c:tempsomefil*
If it’s a folder/directory you’re trying to delete use the rd or rmdir command, e.g.:
rd /s "\?C:Documents and SettingsUserDesktopAnnoying Folder."
Tip: as you’re typing the file/directory name use the TAB key to auto-complete the name (press TAB repeatedly to cycle through possible names).
Of course the corollary of all of this is that you could really annoy somebody by doing this:
echo Hi > "\?%USERPROFILE%DesktopAnnoying file you can't delete."
But you wouldn’t do that would you?
If this post helped you and you feel so inclined, feel free to buy me a beer 🙂